
유니코드와 UTF
전 세계 모든 문자를 전산에서 일관된 표현으로 다룰 수 있도록 설계된 산업표준.
유니코드를 실제로 저장하는 방식은 UTF.
유니코드 스칼라
크기가 가변적인 String 문자열을 하나하나 개별적으로 접근하기 위한 방법.
Unicode기반 21-bit 코드.
UTF-32랑 거의 동일.
하나 이상의 Unicode Scalar가 모여 Character를 이룸.
let code = 0xAC00
let scalar = UnicodeScalar(code)!
let string = "\(scalar)" // 가
let 가 = "\u{AC00}" // 가
한글 유니코드
주로 쓰이는 한글 유니코드
- 초성 19개 1100(4352) ~ 1112(4370)
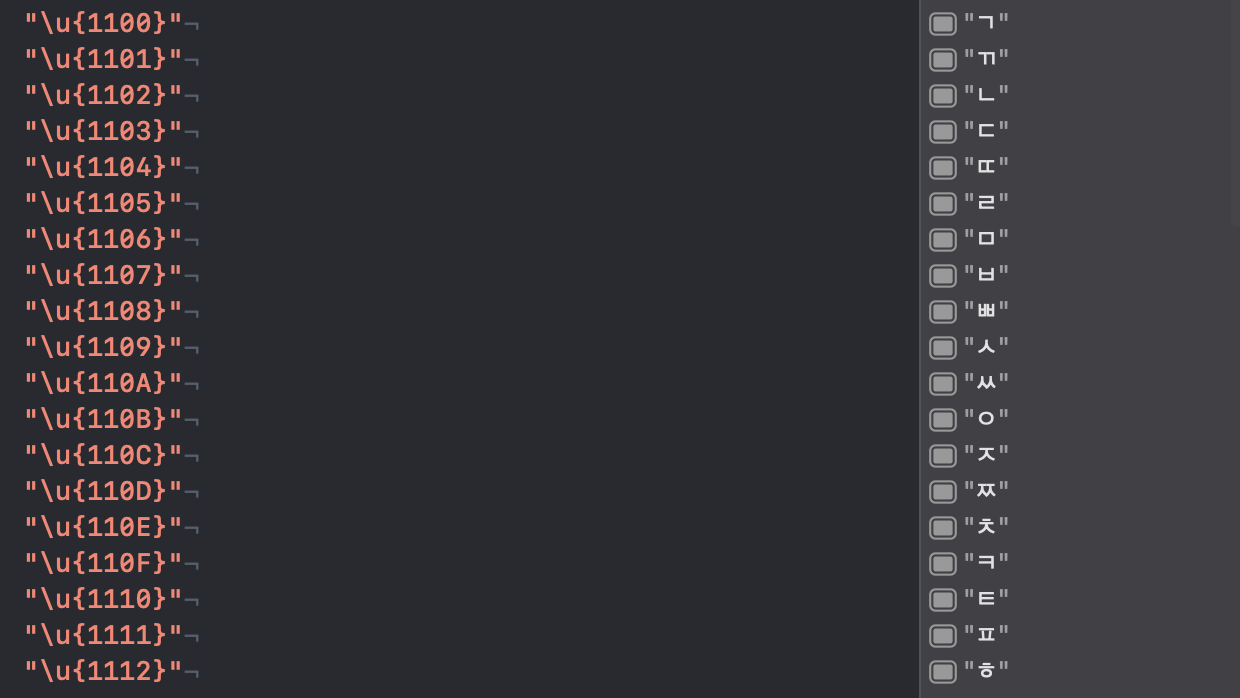
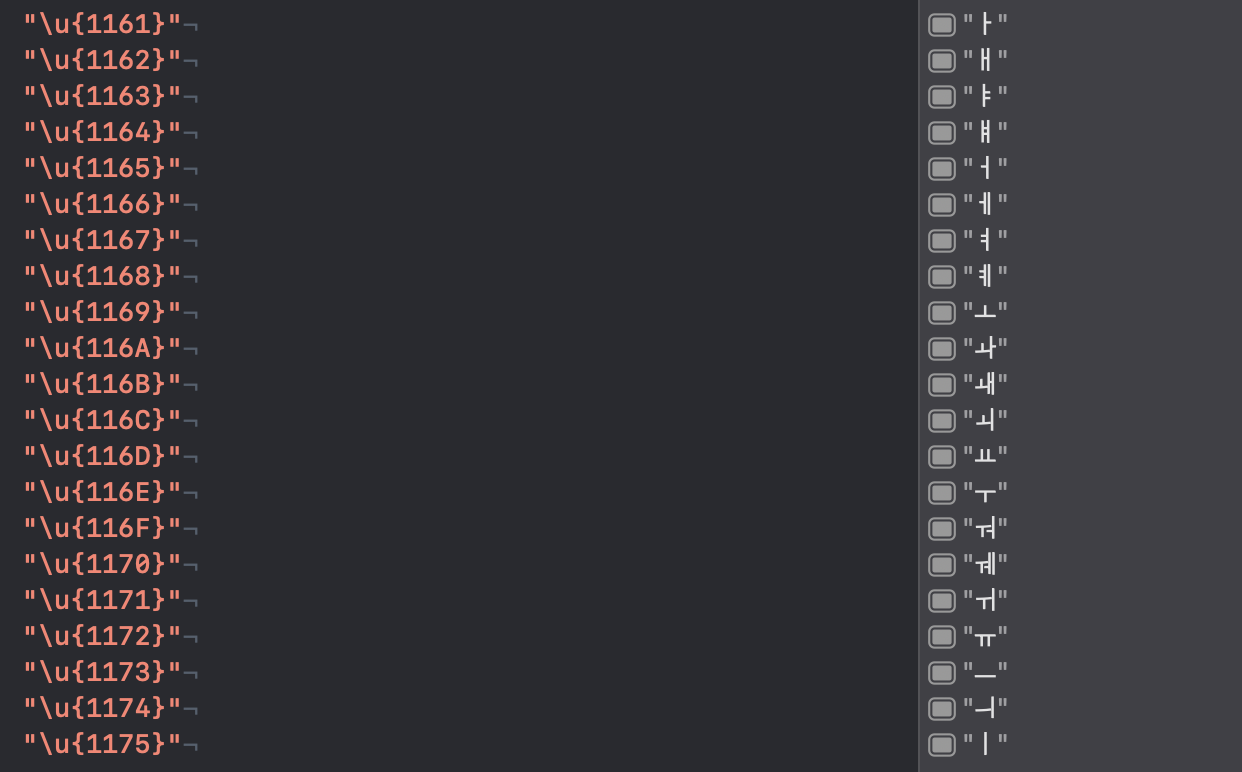
- 중성 21개 1161(4449) ~ 1175(4469)
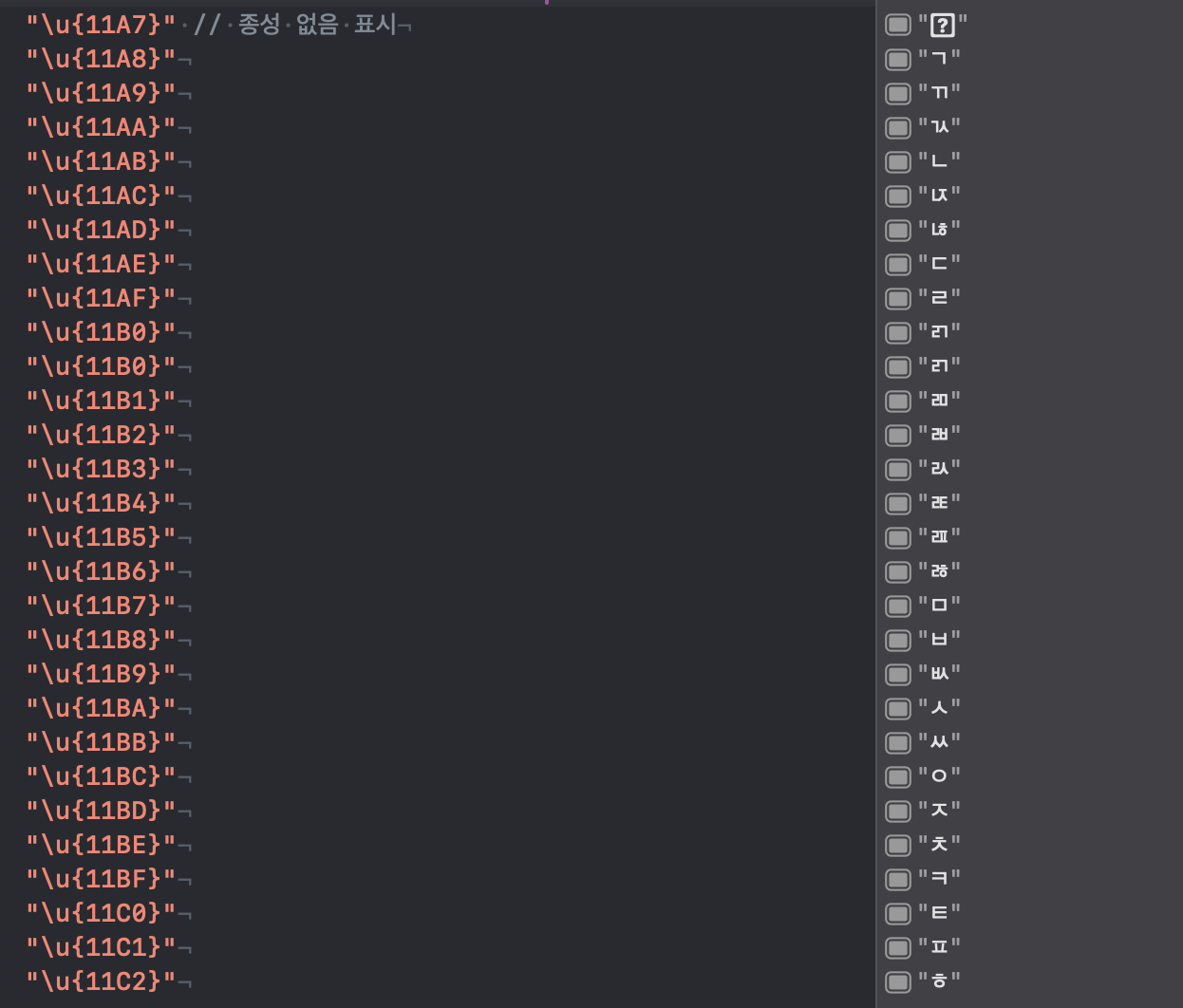
- 종성 28개 11A7(4519) ~ 11C2(4546)
- 한글 음절 코드포인트 11172개

그 외의 한글 유니코드
외에도 아래와 같은 한글 유니코드 테이블이 있습니다.
- Currency Symbols 중 WON SIGN(20A9)
- CJK Symbols and Punctuation 중 HANGUL DOT TONE MARK(302E ~ 302F)
- Hangul Compatibility Jamo(3130 ~ 318F)
- Enclosed CJK Letters and Months 중 한글/한국어 부분(3200 ~ 321E, 3260 ~ 327F)
- Hangul Jamo Extended-A(A960 ~ A97F)
- Hangul Jamo Extended-B(D7B0 ~ D7FF)
- Halfwidth and Fullwidth Forms 중 Halfwidth Hangul variants 부분(FFA0 ~ FFDC)
- Halfwidth and Fullwidth Forms 중 FULLWIDTH WON SIGN(FFE6)
Unicode Equivalence(등가성)
‘특정한 일련의 코드포인트들이 반드시 동일 문자를 대표해야 한다’는 인코딩 표준 사양.
display(인쇄와 출력)을 할 때, 동일한 모양과 의미를 가질 것.
(Xcode가 에디터로 우리에게 코드를 보여주는 것 또한 display해주는 것)

유니코드 정규화
유니코드는 화면상으로 동일하게 보여도 다른 바이트로 저장될 수 있음. 유니코드 문자열을 처리할 때는 실제로 다른 방법으로 저장될 수 있다는 점을 염두해두어야 함.
정규화: 모양이 같은 여러 문자들이 있을 경우 이를 기준에 따라 한가지 기준으로 통합해주는 일.
NFC, NFD, NFKC, NFKD 방식이 있음.
NFD(Normalization Form - Decomposition)
모든 음절을 Canonical Decomposition(정준분해)하여 저장하는 방식.
예시: “각” 문자열을 “ㄱ”, “ㅏ”, “ㄱ” 으로 저장.
NFC방식보다 큰 텍스트 사이즈로 저장됨.
MacOS, iOS에서 주로 사용됨.
// NFD
for scalar in "각".decomposedStringWithCanonicalMapping.unicodeScalars {
print(scalar, scalar.utf8)
}
출력
ᄀ UTF8View(value: "\u{1100}")
ᅡ UTF8View(value: "\u{1161}")
ᆨ UTF8View(value: "\u{11A8}")
💡 iOS에서 파일입출력시 NFD로 String을 다루기 때문에,
- 파일 저장시 파일명 count는 NFD기준으로 해야하고,
- 파일을 불러온 뒤 파일명 String또한 NFD로 정준분해된 상태이기 때문에, 어딘가로 파일명을 전달시 NFC로 처리후 전달해야 함.
NFC(Normalization Form - Composition)
모든 음절을 Canonical Decomposition(정준분해)한 후 Canonical Composition(정준결합)하여 저장하는 방식.
예시: “각” 문자열을 “각”으로 저장.
NFD방식보다 작은 텍스트 사이즈로 저장됨.
Linux, Windows에서 주로 사용.
// NFC
for scalar in "각".precomposedStringWithCanonicalMapping.unicodeScalars {
print(scalar, scalar.utf8)
}
출력
각 UTF8View(value: "\u{AC01}")
NFC, NFD를 하여도 호환이 됨.
"각".decomposedStringWithCanonicalMapping == "각".precomposedStringWithCanonicalMapping
출력
true
NFKD
코드를 호환분해하여 저장하는 방식.
for scalar in "각".decomposedStringWithCompatibilityMapping.unicodeScalars {
print(scalar, scalar.utf8)
}
출력
ᄀ UTF8View(value: "\u{1100}")
ᅡ UTF8View(value: "\u{1161}")
ᆨ UTF8View(value: "\u{11A8}")
NFKC
코드를 호환분해한 후, 다시 정준 결합하여 저장하는 방식.
for scalar in "각".precomposedStringWithCompatibilityMapping.unicodeScalars {
print(scalar, scalar.utf8)
}
출력
각 UTF8View(value: "\u{AC01}")
- 호환 분해: 호환분해는 단순 분리만 하지 않고, 해당 문자의 특수기호까지 정규화를 시켜줌.
let 원문자ㄱ = "㉠"
// NFC
원문자ㄱ.precomposedStringWithCanonicalMapping // ㉠
// NFD
원문자ㄱ.decomposedStringWithCanonicalMapping // ㉠
// NFKC
원문자ㄱ.precomposedStringWithCompatibilityMapping // ㄱ
// NFKD
원문자ㄱ.decomposedStringWithCompatibilityMapping // ㄱ
유니코드 호환성
let ㄱ = "\u{1100}"
let ㅏ = "\u{1161}"
let nfc가 = "\u{ac00}"
let nfd가 = "\u{1100}\u{1161}"
ㄱ + ㅏ == nfc가 // true
ㄱ + ㅏ == nfd가 // true
nfc가 == nfd가 // true
nfc가 == "가" // true
nfd가 == "가" // true// NFD, NFC
"가".decomposedStringWithCanonicalMapping == "가".precomposedStringWithCanonicalMapping
// truelet 초성ㄱ = "\u{1100}"
let 종성ㄱ = "\u{11A8}"
초성ㄱ == 종성ㄱ // false
초성ㄱ == "ㄱ" // false
종성ㄱ == "ㄱ" // false// NFKC
초성ㄱ == "ㄱ".precomposedStringWithCompatibilityMapping // true
// NFKD
초성ㄱ == "ㄱ".decomposedStringWithCompatibilityMapping // true
count와 length의 차이
- String.count: count는 display되는 문자열을 기준으로 카운팅.
let 가: String = "\u{1100}\u{1161}"
가.count // 1
- NSString.length: NSString의 length는 문자열의 UTF-16 표현에 포함된 16비트 코드 단위의 수를 기준으로 정해짐.
let ns가: NSString = "\u{1100}\u{1161}"
ns가.length // 2let ns가 = "\u{1100}\u{1161}".precomposedStringWithCanonicalMapping as NSString
ns가.length // 1